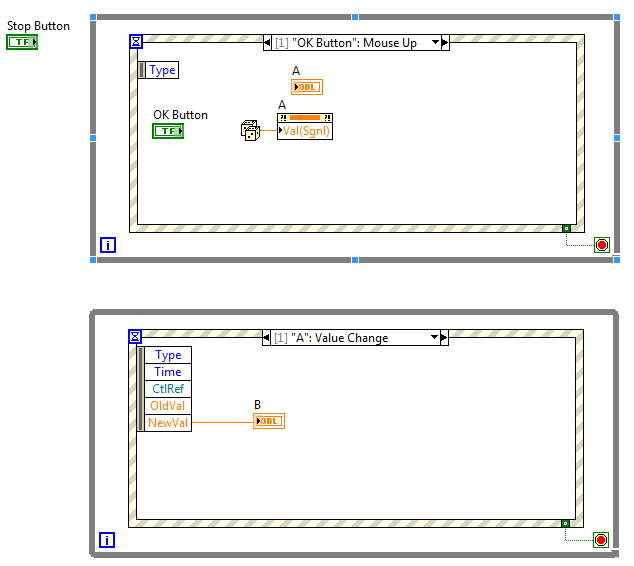
Ciekawy sposób, na przesłanie wartości pomiędzy dwiema równoległymi pętlami.
Właściwość Value (Signaling) oprócz ustawienia wartości kontrolki, powoduje wysłanie zdarzenia Value Change.
Baza wiedzy mvlab → Posty przez Dariusz Tryba
Ciekawy sposób, na przesłanie wartości pomiędzy dwiema równoległymi pętlami.
Właściwość Value (Signaling) oprócz ustawienia wartości kontrolki, powoduje wysłanie zdarzenia Value Change.
Podstawy tworzenia tablic
Odczytywanie rozmiaru tablicy, suma elementów tablicy
Indeksowanie tablic
Polimorfizm w tablicach, kontrolka Build Array
Inicjalizacja tablicy
Tworzenie tablicy poprzez automatyczne indeksowanie wyjścia pętli For
Automatyczne indeksowanie tablic w pętli For
Praca z tablicami wielowymiarowymi
Automatyczna konkatenacja tablic w pętli
Terminal warunkowy na wyjściu pętli For
Rejestry przesuwne to mechanizm, który umożliwia przekazywanie wartości z końca jednej iteracji na początek kolejnej. Bardzo dobrze ilustruje to poniższy film:
Poniżej przykładowe programy, wykorzystujące ten mechanizm.
Uwaga do powyższego filmu: wskazane było by dopasowanie typu kontrolki Numeric tak, aby nie następowało rzutowanie.
Na poniższym filmie przedstawiona jest ciekawa technika, dzięki której wykorzystując zdarzenie Timeout oraz kontrolkę First Call? możemy sprawić, aby wybrane zdarzenie zostało wywołane samoczynnie przy starcie aplikacji.
Ograniczeniem tej techniki jest to, że zdarzenie Timeout może być obsługiwane tylko przez jeden subdiagram struktury Event. Możemy w ten sposób uruchomić więc tylko jedno wybrane zdarzenie.
Polecam poniższe ustawienia konfiguracyjne:
Odpowiednik komentarzy blokowych
/* */Dołączam zdarzeniową wersję programu przeliczającego temperaturę i skale.
Przykładowy program przeliczający temperaturę warto zmodyfikować tak, aby skala termometru automatycznie dopasowywała się do tego, czy konwersja jest załączona czy wyłączona. Aktualnie jest ona ustawiona z odpowiednim zapasem, tak aby każda wartość wejściowa (przeliczona czy nie) znalazła się w jej zakresie.
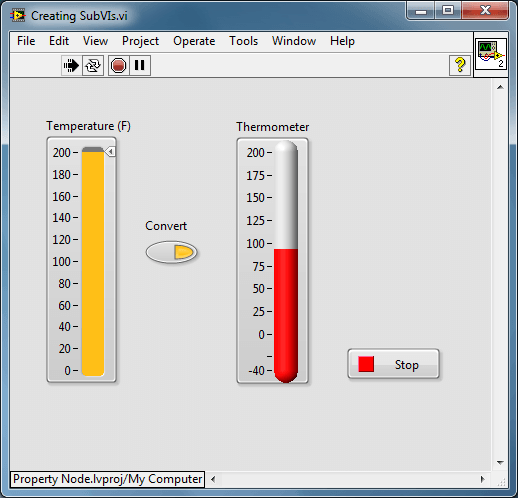
Rysunek 1 Program wyjściowy.
Do zwykłych kontrolek, czy też poprzez mechanizm zmiennych lokalnych, możemy jedynie podpinać przewody ustawiające ich główne wartości. Do programowej zmiany dowolnej właściwości, służy kontrolka Property Node.
Program zmodyfikujemy tak, aby skala suwaka była odczytywana i w zależności od ustawienia przycisku, przeliczana na skalę odpowiednią dla termometru.
W celu odczytania skali suwaka, klikamy w oknie diagramu blokowego prawym przyciskiem myszy na jego kontrolce i wybieramy opcję Create -> Property Node -> Scale -> Range -> Minimum.
Powstałą w ten sposób kontrolkę możemy rozciągnąć, a klikając na drugiej wartości wybieramy Scale -> Range -> Maximum.
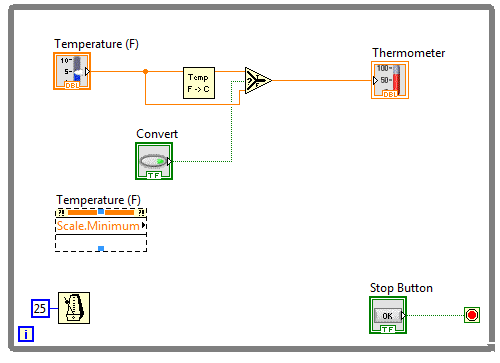
Rysunek 2 Umieszczenie na diagramie kontrolki Property Node.
Analogicznie postępujemy dla kontrolki termometru. Po wskazaniu odpowiednich właściwości klikamy prawym przyciskiem myszy na kontrolkę Property Node dla termometru i wybieramy opcję Change All To Write. Spowoduje to zmianę wszystkich jej terminali z wyjściowych na wejściowe.
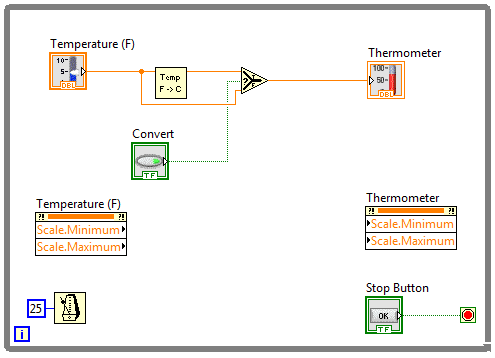
Rysunek 3 Kontrolki Property Node umieszczone na diagramie blokowym.
Do przeliczenia skali użyjemy przygotowany wcześniej podprogram konwertujący temperaturę.
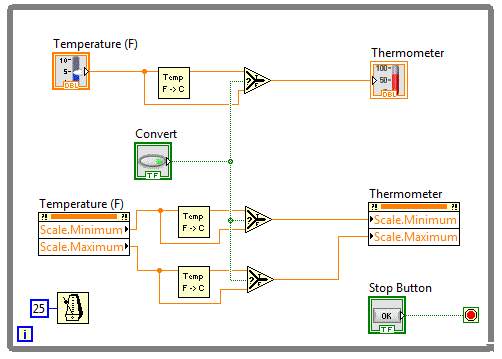
Rysunek 4 Gotowy program przeliczający skale kontrolek.
Propozycje ćwiczeń i modyfikacji
Dopasować właściwości termometru tak, aby wartości wyświetlały się z dokładnością do jednego miejsca po przecinku i nie wychodziły poza kontrolkę
Dodać programową zmianę nazwy kontrolki termometru tak, aby było to odpowiednio "Temperature (F)" i "Temperature (C)" w zależności od wartości przycisku
Dodać wyświetlacz cyfrowy wartości temperatury, którego kolor tła zmienia się w zależności od wartości
Sposób tworzenia podprogramów w LabVIEW dobrze ilustruje poniższy film:
Uwagi do powyższego filmu i tematu tworzenia podprogramów:
- Nazwy kontrolek podprogramu powinny więcej mówić o tym, co dana kontrolka oznacza, czyli zamiast Numeric powinno być Temperature (C)
- Zgodnie z ogólną zasadą programowania, mówiącą, że funkcja powinna wykonywać tylko jedną czynność, przekazywanie w tym przypadku argumentu boolowskiego należy raczej uznać za złą praktykę (a na pewno nie powinien on nazywać się Boolean). Taki argument powoduje, że podprogram wykonuje dwie czynności - przelicza wartość albo nie przelicza. Tę funkcjonalność należało by potraktować tutaj jedynie jako przykład szkoleniowy, a docelowo wyprowadzić na zewnątrz (patrz zmodyfikowany program poniżej).
- W projekcie warto utworzyć sobie osobny wirtualny folder na podprogramy. W przypadku prostych aplikacji wystarczy jeden (np. SubVI), w przypadku bardziej złożonych dobrze pogrupować je według realizowanych funkcji (np. Akwizycja Danych, Obliczenia itp.).
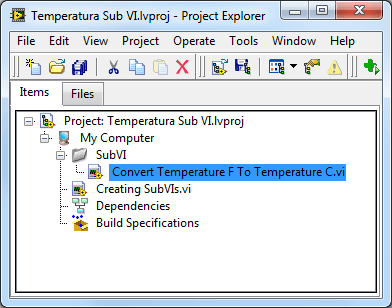
Rysunek 1 Wirtualny folder w projekcie
- W nowszych wersjach LabVIEW nie ma już potrzeby przełączania się pomiędzy ikoną a terminalami, są one pokazane obok siebie w oknie Front Panel.
- Zalecany schemat połączeń dla podprogramów to 4-2-2-4. Jest to też schemat domyślnie ustawiany zawsze podczas tworzenia podprogramu. W przypadku bardzo prostych operacji jak powyższa, dobrym rozwiązaniem jest również najprostsze 1-1.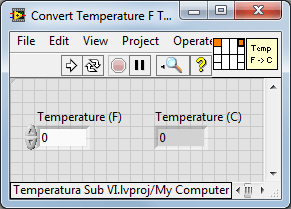
Rysunek 2 Panel frontowy podprogramu, własna ikona i domyślny schemat połączeń
Poniżej załączam również zmodyfikowany program.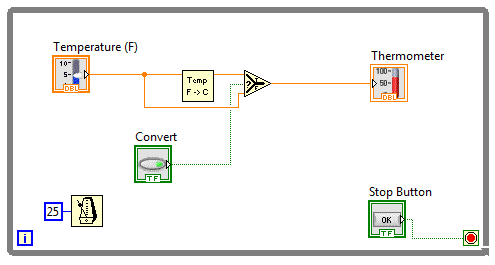
Rysunek 3 Zmodyfikowana wersja programu
Podstawy
Konfiguracja LabVIEW
Wprowadzenie do LabVIEW i pierwszy program
Tworzenie podprogramów
Programowa zmiana właściwości kontrolek - Property Node
Struktura Case
Programowanie zdarzeniowe
Rejestry przesuwne
Tablice
Deaktywowanie fragmentów diagramu blokowego
Wskazówki i triki
Techniki Programowania
Wywołanie zdarzenia raz przy starcie aplikacji
Obsługa portu szeregowego
Zdarzeniowa obsługa przycisku fizycznego
Wizualizacja danych z uwzględnieniem pól tolerancji
Klawiatura ekranowa z wykorzystaniem referencji
Zrównoleglanie czasochłonnych operacji
Korzystanie z dodatkowych bibliotek
Jeżeli chcemy "pokolorować" obraz w skali szarości, musimy opracować sobie przekształcenie, w którym każdej wartości ze skali szarości odpowiada zestaw trzech składowych barwnych R, G i B.
Do tego celu możemy skorzystać z programu typu Paint.
Na przykład jeżeli chcemy zrobić przejście od koloru żółtego do czerwonego to możemy sprawdzić, że kolor żółty ma składowe:
[255, 255, 0]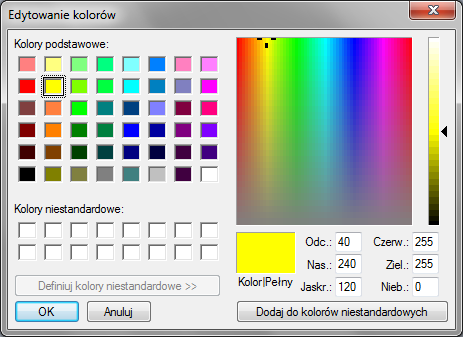
Kolor czerwony natomiast [255, 0, 0]
Gradient od żółtego do czerwonego będzie więc wyglądał tak:
[255, 255, 0]
[255, 254, 0]
...
[255, 0, 0]
Następnie zamieniając jasności poszczególnych pikseli na zestaw RGB i zapisując obraz jako PPM, uzyskamy efekt nałożenia na obraz mapy kolorów:


Aby przejście obejmowało więcej kolorów należy dodać więcej punktów pośrednich, zmieniając w sposób liniowy poszczególne wartości pomiędzy nimi.
Dobrym nawykiem programistycznym jest ograniczanie czasu życia zmiennych. Sprowadza się to do tworzenia zmiennych tylko jeżeli są rzeczywiście potrzebne, aby ich zakres istnienia był jak najkrótszy.
Co prawda używamy kompilatora, który trzyma się zasady, że zmienne mogą być deklarowane tylko na początku bloków kodu, ale to wcale nie znaczy, że wszystkie zmienne muszą zostać zadeklarowane na początku funkcji (deklaracje mogą się znaleźć tylko bezpośrednio po otwierających nawiasach klamrowych).
Weźmy dla przykładu prostą funkcję zapisującą dane do pliku:
int zapiszPlik(char* nazwaPliku) {
FILE* plik;
int liczbaProbek = 10;
int i;
plik = fopen(nazwaPliku, "r");
if (plik == NULL) {
printf("Nie udalo sie otworzyc pliku!");
return 1;
} else {
for (i = 0; i < liczbaProbek; i++) {
fprintf(plik, "%d\n", i);
}
fclose(plik);
}
return 0;
}Zmienne i oraz liczbaProbek nie są do niczego potrzebne, jeżeli okaże się, że pliku nie udało się otworzyć, możemy więc zadeklarować je później:
int zapiszPlik(char* nazwaPliku) {
FILE* plik;
plik = fopen(nazwaPliku, "r");
if (plik == NULL) {
printf("Nie udalo sie otworzyc pliku!");
return 1;
} else {
int liczbaProbek = 10;
int i;
for (i = 0; i < liczbaProbek; i++) {
fprintf(plik, "%d\n", i);
}
fclose(plik);
}
return 0;
}Taki zabieg powinien również wpłynąć korzystnie na czytelność kodu, gdyż deklaracje zmiennych znajdą się bliżej miejsca ich użycia. Ponadto łatwiejsze staje się podzielenie programu na mniejsze funkcje.
W C++ (jak również w nowszym standardzie C) nie ma już takiego ograniczenia, zmienne możemy deklarować w dowolnych miejscach, w momentach kiedy są potrzebne.
Z wyciekiem pamięci (ang. memory leak), mamy do czynienia w sytuacji, gdy nie zwalniamy zaalokowanego wcześniej obszaru pamięci, a tracimy do niego dostęp.
Wycieki pamięci mogą pozostawać niezauważone, jednak są szczególnie groźne w sytuacji gdy nasze programy pracują przez dłuższy czas w sposób ciągły.
Porządnie napisany program nie powinien wykazywać żadnych wycieków pamięci!
Najczęstsze błędy, które prowadzą do wycieku to:
- zwyczajnie niezwolnienie zaalokowanej pamięci poprzez pominięcie wywołania funkcji free
- przypisanie do wskaźnika nowo zaalokowanej pamięci bez zwolnienia pamięci, na którą wskazywał on wcześniej (przy założeniu, że jest to jedyny wskaźnik na ten obszar pamięci, i dane w tym obszarze nie są już potrzebne)
- zachowanie użytkownika różne od oczekiwań i przyzwyczajeń autora programu, powodujące sekwencję czynności prowadzącą do tego, że program się kończy przed operacją zwalniającą pamięć (bo np. zwolnienie pamięci jest jako osobna opcja w menu, a użytkownik wybrał od razu opcję wyjścia z programu)
Aby uniknąć wycieku pamięci należy kierować się prostą zasadą:
Funkcja free powinna zostać wywołana w programie dokładnie tyle samo razy, co funkcja malloc (lub calloc).
Przydatnym narzędziem do wykrycia, czy w naszym programie w Visual Studio pojawiają się wycieki pamięci jest Visual Leak Detector.
Instrukcja użycia:
1. Pobieramy i instalujemy VLD
2. Uruchamiamy Visual Studio, otwieramy nasz projekt lub tworzymy nowy, a następnie wybieramy z menu View opcję Property Manager.
Rozwijamy Visual Leak Detector -> Debug | Win32 i klikamy dwukrotnie Microsoft.Cpp.Win32.user.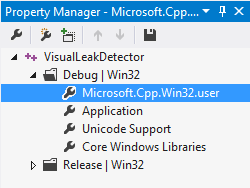
W oknie w zakładce VC++ Directories dla opcji "Include Directories" oraz "Library Directories" dodajemy ścieżki do odpowiednich folderów w miejscach, gdzie zainstalował się VLD:
- dla Include Directories może to być na przykład C:\Program Files\Visual Leak Detector\include
- dla Library Directories będzie to na przykład C:\Program Files\Visual Leak Detector\lib\Win32
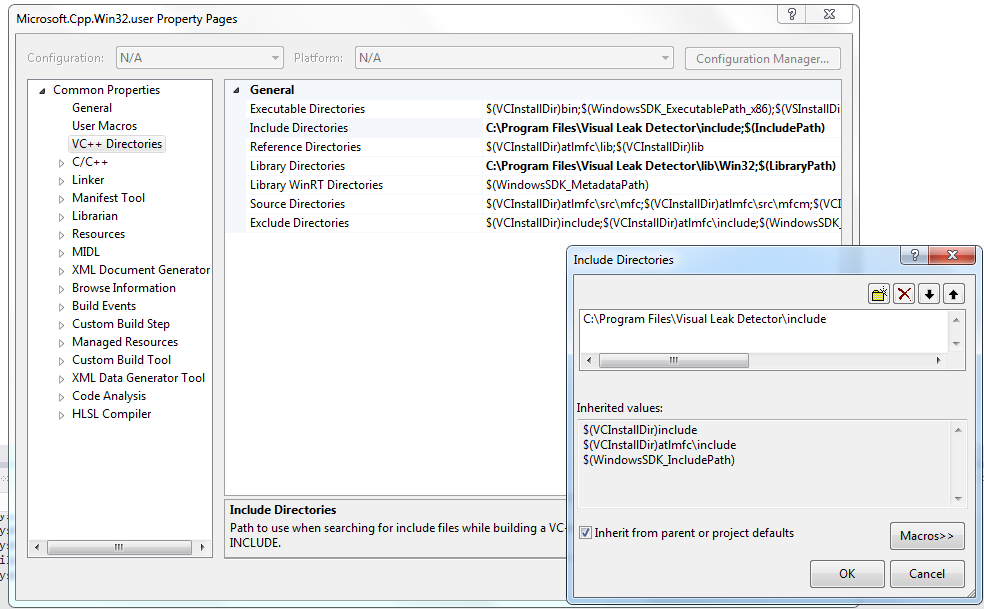
(Jeżeli piszemy aplikacje 64 bitowe, to to samo robimy dla Microsoft.Cpp.Win64.user, tylko w bibliotekach wskazujemy folder Win64).
3. Na etapie opracowywania programu, dołączamy do niego plik nagłówkowy <vld.h> po <stdlib.h>
Dołączenie tego pliku spowoduje, że po każdym uruchomieniu programu VLD poinformuje nas o ewentualnych wyciekach.
Po zakończeniu pracy nad programem i upewnieniu się, że nie ma żadnych wycieków, usuwamy dołączanie pliku <vld.h>
Przykład
Prosty program z wyciekiem pamięci:
#include <stdlib.h>
#include <vld.h>
void main() {
int* tab;
tab = (int*) malloc(100 * sizeof(int));
}Efekt jego uruchomienia:
Visual Leak Detector detected 1 memory leak (436 bytes).
Largest number used: 436 bytes.
Total allocations: 436 bytes.
Jeżeli chcemy sprawdzić co pozostało nie zwolnione, w oknie Output odszukujemy sekcję Call Stack. Klikając dwukrotnie na linijkę dotyczącą naszego programu, zostaniemy przeniesieni do fragmentu kodu, w którym nastąpiła alokacja pamięci:
Call Stack:
c:\users\administrator\desktop\visualleakdetector\visualleakdetector\main.c (6): VisualLeakDetector.exe!main + 0xD bytes
Program naprawiony poprzez dodanie wywołania funkcji free():
#include <stdlib.h>
#include <vld.h>
void main() {
int* tab;
tab = (int*) malloc(100 * sizeof(int));
free(tab);
}No memory leaks detected.
Załączam program, który dokonuje konwersji dowolnego zdjęcia do formatu PGM, PBM lub PPM
Tego typu błąd może pojawić się podczas uruchomienia programu w trybie debugowania (F5 - Start Debugging).
Oznacza on, że próbujemy dostać się (odczytać / zapisać) do obszaru pamięci, do którego dostęp jest zabroniony.
Należy wówczas przyjrzeć się dokładnie kodowi, a najczęstsze powody takiego błędu to na przykład:
- do funkcji typu scanf przekazaliśmy wartość zmiennej, a nie jej adres
- zadeklarowaliśmy tylko wskaźnik na dynamiczny obszar pamięci, ale zapomnieliśmy o zaalokowaniu tego obszaru,
- przechodząc po elementach tablicy wychodzimy zbyt daleko w pamięć (bo np. w pętli for mamy <=, a powinno być <), lub jeżeli odejmujemy jakieś wartości od indeksów tablicy, pojawiają się indeksy ujemne
- pomyliliśmy wysokość tablicy dwuwymiarowej z jej szerokością, zamieniając indeksy lub warunki stopu pętli for miejscami
Nierzadko miejsca powodujące te błędy możemy wytropić dokładnie czytając i eliminując do zera wszystkie ostrzeżenia, jakie zgłasza nam kompilator!
W przypadku gdy projekt ze starszej wersji otwieramy w nowszej, z reguły środowisko samo zapyta czy go uaktualnić, po czym nie powinien on już wymagać dalszych zabiegów.
Jeżeli otwieramy projekt z nowszej wersji w starszej, może się nam on otworzyć poprawnie, jednak zgłaszać błędy i nie dawać się skompilować.
W takiej sytuacji powinno wystarczyć przestawienie opcji Platform Toolset we właściwościach projektu (Project -> Properties... Alt + F7).
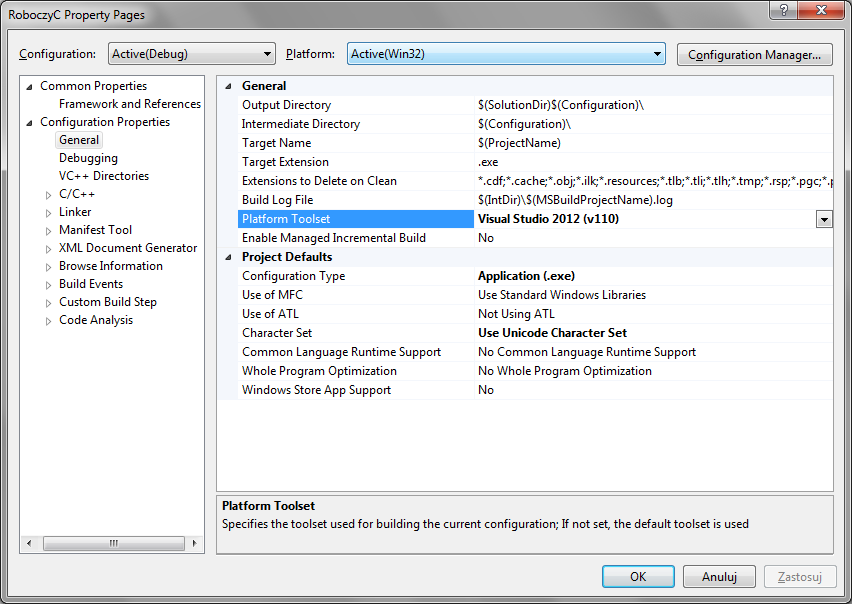
Jeżeli na przykład mamy VS2010, a otwieramy projekt z 2012, to trzeba tam przestawić z v110 na v100.
Don't Repeat Yourself
Jeżeli w programie zauważamy, że jakieś czynności się powtarzają, to jest to pierwsza przesłanka do tego, żeby pomyśleć nad utworzeniem z nich osobnej funkcji.
Funkcja powinna robić dobrze jedną rzecz
Jeżeli deklarujemy, że funkcja coś oblicza, to powinna obliczać, a nie jeszcze dodatkowo dopytywać się o coś użytkownika (to powinna robić inna funkcja).
Jeżeli deklarujemy, że funkcja dodaje do siebie dwie tablice, to powinna dodawać, a nie jeszcze zapisywać do pliku (to powinna robić osobna funkcja).
Nie mieszamy w jednej funkcji czynności związanych z interakcją z użytkownikiem z czynnościami związanymi z przetwarzaniem danych, pracą z systemem plików, to wszystko powinno zostać podzielone na osobne funkcje.
Pomocne w tym jest stosowanie się do wytycznych w zakresie nazewnictwa. Jeżeli nazywamy funkcje według szablonu zrób_coś() pomaga nam to w zapewnieniu, że funkcja robi tylko to.
Funkcja powinna być najkrótsza jak się da
Stosowanie tej zasady wymusza na nas podział programu na jak największą liczbę jak najkrótszych funkcji, co przy okazji sprawia, że eliminujemy powtórzenia i tworzymy funkcje, które rzeczywiście robią jedną rzecz. Ortodoksyjne podejście zakłada maksymalną długość funkcji jako około 5 linijek, co może nie być na początku łatwe, ale jest to pewien ideał, do którego warto dążyć.
Funkcja powinna dawać możliwość ponownego użycia
Staramy się tak pisać funkcje, aby maksymalizować ich uniwersalność i możliwość ich ponownego użycia.
Techniką, która pomaga osiągnąć jak największą uniwersalność kodu jest wydzielanie z funkcji mniejszych funkcji tak długo, aż stwierdzimy, że nic więcej nie da się wydzielić. Efektem jest program z dużą liczbą niewielkich funkcji, z których każda wykonuje jedną, precyzyjnie określoną operację.
Redukujemy sprzężenia czasowe pomiędzy funkcjami
Staramy się pisać program tak, aby poprawne działanie funkcji nie było uzależnione od wcześniejszego wywołania innej.
Wskazówka
Jeżeli widzimy w programie blok kodu, który jest opatrzony komentarzem, to jest to dobra kandydat na wydzielenie funkcji i usunięcie komentarza.
Przykład 1
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
double obliczPoleKwadratu() {
double dlugoscBoku;
printf("Podaj dlugosc boku: ");
scanf("%lf", &dlugoscBoku);
return dlugoscBoku * dlugoscBoku;
}
void main() {
double pole;
pole = obliczPoleKwadratu();
}Funkcja obliczPoleKwadratu robi dwie rzeczy - dopytuje się użytkownika o długość boku i oblicza pole.
Wersja poprawiona:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
double obliczPoleKwadratu(double dlugoscBoku) {
return dlugoscBoku * dlugoscBoku;
}
void main() {
double dlugoscBoku;
double pole;
printf("Podaj dlugosc boku: ");
scanf("%lf", &dlugoscBoku);
pole = obliczPoleKwadratu(dlugoscBoku);
}Ze sprzężeniem czasowym (temporal coupling) pomiędzy funkcjami mamy do czynienia wówczas, gdy do poprawnego działania jednej funkcji, konieczne jest wcześniejsze wywołanie jakiejś innej funkcji.
Sytuacja taka jest bardzo niekorzystna, ponieważ zwiększa tzw. kruchość systemu, czyli podatność na awarię jednego modułu, po dokonaniu zmiany w innym. A to prowadzi do zwiększonego lęku przed wprowadzaniem zmian i ulepszeń, "żeby czegoś nie zepsuć".
Dlatego powinniśmy mieć to na uwadze, minimalizować takie sprzężenia czasowe i dbać o to, aby funkcje były maksymalnie samowystarczalne.
Dobrym przykładem może być losowanie liczb.
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
void inicjalizuj_generator() {
srand((unsigned)time(NULL));
}
int losuj(int zakres) {
return rand() % zakres;
}
int main(void) {
inicjalizuj_generator();
printf("%d\n", losuj(10));
printf("%d\n", losuj(10));
return 0;
}W powyższym przykładzie poprawne działanie funkcji losuj() uzależnione jest od wcześniejszego wywołania funkcji inicjalizuj_generator(), między tymi funkcjami zachodzi więc sprzężenie (bez inicjalizacji, przy każdym uruchomieniu programu losowane były by te same liczby).
Aby zniwelować to sprzężenie, funkcja losuj() powinna sama zadbać o wszystko co jest jej potrzebne do poprawnego działania, czyli również o zainicjalizowanie generatora.
Jeżeli jednak wywołamy funkcję inicjalizuj_generator() w funkcji losuj():
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
void inicjalizuj_generator() {
srand((unsigned)time(NULL));
}
int losuj(int zakres) {
inicjalizuj_generator();
return rand() % zakres;
}
int main(void) {
printf("%d\n", losuj(10));
printf("%d\n", losuj(10));
return 0;
}to program nie będzie działał poprawnie, gdyż ciągłe inicjalizacje spowodują, że losowana będzie taka sama liczba.
Rozwiązaniem jest zapewnienie, że inicjalizacja generatora liczb pseudolosowych zostanie wykonana tylko raz w ciągu całego działania programu. Do tego celu możemy wykorzystać zmienne statyczne (czyli zmienne, które pamiętają swoje wartości pomiędzy kolejnymi uruchomieniami funkcji).
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
void inicjalizuj_generator() {
static int zainicjalizowany = 0;
if (!zainicjalizowany) {
srand((unsigned)time(NULL));
zainicjalizowany = 1;
}
}
int losuj(int zakres) {
inicjalizuj_generator();
return rand() % zakres;
}
int main(void) {
printf("%d\n", losuj(10));
printf("%d\n", losuj(10));
return 0;
}Takie rozwiązanie sprawia, że funkcja losuj() sama posiada wszystko co potrzeba do jej prawidłowego działania, nie jest uzależniona od żadnych zewnętrznych "magicznych" czynników.
Natomiast można by się teraz zastanowić, czy funkcja inicjalizuj_generator() po zmianach nie wymaga nadania lepszej nazwy.
Rozwiązanie, które zapewnia nam, że coś zostanie wykonane tylko raz, nosi nazwę singleton.
Zwracam uwagę, że Visual Studio kompiluje tylko te pliki, które zostały dodane do projektu i są widoczne w folderze Source Files okna Solution Explorer.
Dlatego jeżeli napiszemy program na laboratorium, a następnie sam plik z kodem źródłowym prześlemy sobie i otworzymy w domu w Visual Studio, może okazać się, że nie będzie w ogóle opcji kompilacji lub kompilował i uruchamiał się będzie jakiś stary program.
Dlatego należy taki plik skopiować do folderu z projektem, a następnie dodać do Source Files (przez Add -> Existing Item), albo też jego zawartość skopiować do już istniejącego i dodanego do projektu pliku z kodem źródłowym.
Wówczas Visual Studio skompiluje ten kod, nie kompiluje ono kodu plików, które zostały w nim tylko otwarte, bez powiązania z jakimkolwiek projektem.
Jeżeli wykorzystujemy w naszym programie funkcję rand(), należy również pamiętać o poprawnej inicjalizacji generatora liczb pseudolosowych przy pomocy funkcji srand().
W przeciwnym przypadku możemy napotkać dwa objawy niepoprawnego działania:
1. Program przy każdym uruchomieniu losuje ten sam zestaw liczb.
Taka sytuacja występuje, gdy funkcji srand() nie ma wcale, lub do funkcji srand() jest przekazywana zawsze ta sama wartość (np. 0). Dlatego do funkcji srand przekazujemy aktualną wartość licznika milisekund zwracaną przez funkcję time(), by zwiększyć szansę na to, że przy każdym uruchomieniu programu będzie to inna liczba.
2. Program w pętli losuje zawsze jedną i tą samą liczbę.
Taka sytuacja występuje z kolei, gdy funkcja srand() wywoływana jest wielokrotnie. Nawet jeżeli jest w niej użyta funkcja time(), to jeżeli tylko dzieje się to w jednej i tej samej milisekundzie (a z reguł komputer jest wystarczająco szybki aby tak się stało), generator liczb pseudolosowych jest za każdym razem inicjalizowany od nowa tą samą wartością. W takim przypadku należy zadbać o to, aby funkcja srand została wywołana rzadziej, wystarczy raz na początku programu.
Moim zdaniem nazwa funkcji srand niewiele mówi, dlatego proponuję w programie opakować ją w osobną funkcję i tę funkcję wywołać gdzieś na początku programu (wystarczy to zrobić raz).
void inicjalizuj_generator() {
srand((unsigned)time(NULL));
}Załóżmy, że mamy program, w którym dokonujemy akwizycji danych, ich przetwarzania oraz zapisu wyników do pliku. Każda z tych operacji charakteryzuje się określonym czasem trwania. Dla lepszego zobrazowania symulujemy poszczególne operacje przy pomocy podprogramów przedstawionych poniżej.

Rysunek 1 Akwizycja danych, czas trwania 20ms
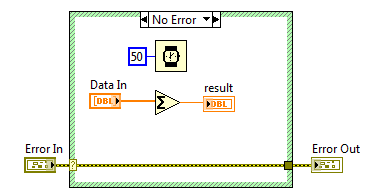
Rysunek 2 Przetwarzanie danych, czas trwania 50ms
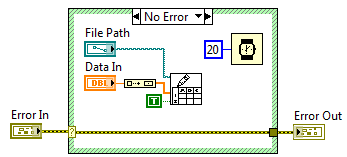
Rysunek 3 Logowanie wyników, czas trwania 20ms
Jeżeli umieścimy poszczególne operacje w jednej pętli while tak, aby były wykonywane sekwencyjnie, całkowity czas wykonania pojedynczej iteracji pętli będzie określony przez sumę czasów wykonania poszczególnych podprogramów, wyniesie więc 90ms.

Rysunek 4 Podprogramy wykonywane sekwencyjnie, pomiar czasu wykonania pojedynczej iteracji pętli
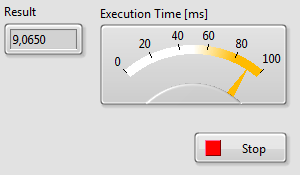
Rysunek 5 Panel frontowy programu, wynik pomiaru czasu wykonania
Taka sytuacja może być dla nas bardzo niepożądana, jeżeli zależy nam na tym, aby akwizycja danych wykonywana była przy najmniejszym możliwym cyklu czasowym. Przy powyższym rozwiązaniu, cykl ten jest ponad 4-krotnie dłuższy.
Rozwiązaniem tego problemu jest zrównoleglenie wykonania poszczególnych operacji poprzez umieszczenie każdego z podprogramów w osobnej, działającej równolegle pętli while.
W tym celu tworzymy na diagramie blokowym dwie dodatkowe pętle while, jako warunek stopu do każdej z nich podpinamy zmienną lokalną dla przycisku Stop Button.
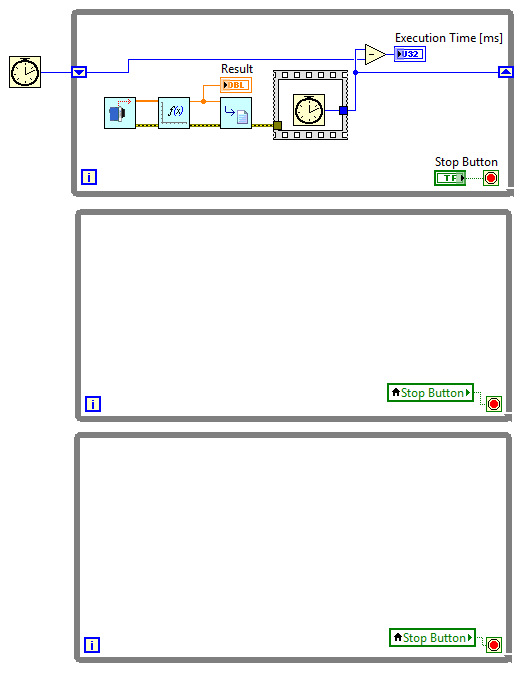
Rysunek 6 Równoległe pętle while
Poszczególne podprogramy nie mogą działać jednak zupełnie niezależnie od siebie, gdyż są ściśle powiązane przepływem danych. W celu przekazania danych do poszczególnych podprogramów, wykorzystamy mechanizm kolejki FIFO (first in first out). Pętla dokonująca akwizycji danych umieszcza pozyskaną w podprogramie Acquire Data tablicę danych w kolejce, z której będą one pobierane w pętli przetwarzającej. Z kolei przetworzone dane są umieszczane w drugiej kolejce, z której następnie pobiera je pętla logująca do pliku.
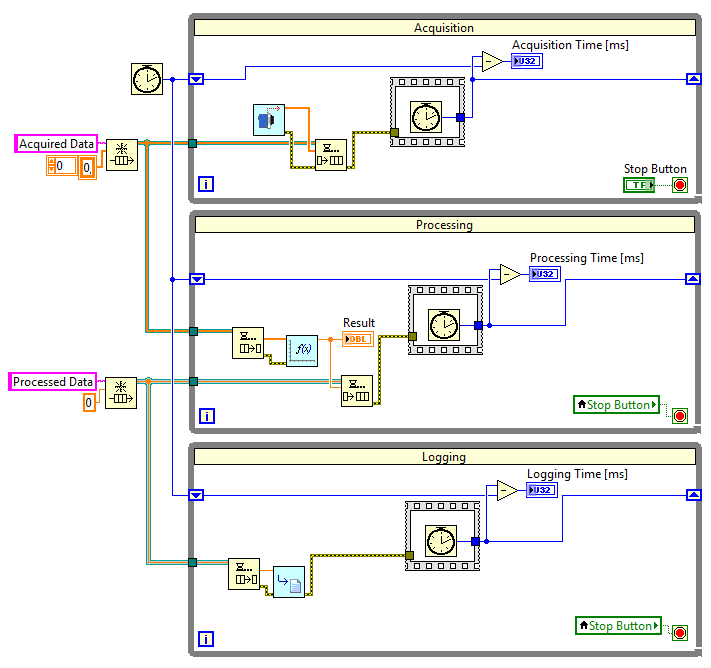
Rysunek 7 Pętle z kolejkami
W celu oprogramowania tego mechanizmu, przenosimy poszczególne podprogramy do osobnych pętli, a następnie wstawiamy na diagram blokowy dwa bloczki Obtain Queue, odpowiedzialne za utworzenie kolejek. Pierwszej kolejce nadajemy nazwę Acquired Data, drugiej Processed Data. Jako typ danych dla pierwszej kolejki podłączamy tablicę liczb typu double, natomiast w przypadku drugiej kolejki – pojedynczą liczbę typu double.
W pierwszej pętli (Acquisition) umieszczamy bloczek Enqueue Element, odpowiedzialny za dodanie elementu do kolejki. Na jego wejścia podpinamy kolejkę oraz tablicę wyjściową z podprogramu Acquire Data.
Elementy dodane do pierwszej kolejki, pobierane są w drugiej pętli (Processing). W tym celu umieszczamy w niej bloczek Dequeue Element, realizujący pobranie pierwszego elementu z kolejki. Element ten następnie podajemy na wejście podprogramu przetwarzającego, a wynik przetwarzania dodajemy do drugiej kolejki wykorzystując ponownie bloczek Enqueue Element.
Wyniki przetwarzania są pobierane z kolejki w pętli Logging w analogiczny sposób przy pomocy bloczka Dequeue Element.
Dodatkowo w każdej z pętli umieszczone zostały bloczki Tick Count, służące do pomiaru czasu iteracji pętli.
Po uruchomieniu programu możemy zauważyć, że poszczególne pętle pracują z najkrótszym możliwym cyklem czasowym.

Rysunek 8 Czasy cyklu każdej z pętli równoległych
Powyższe rozwiązanie nie jest jednak całkowicie poprawne, ponieważ naciśnięcie przycisku Stop powoduje natychmiastowe przerwania działania wszystkich pętli. Efektem tego jest brak przetworzenia i zapisu do pliku wszystkich wygenerowanych danych.
W celu zobrazowania tego efektu możemy dodać do każdej z pętli liczniki iteracji i porównać ich wartości po zakończeniu programu.
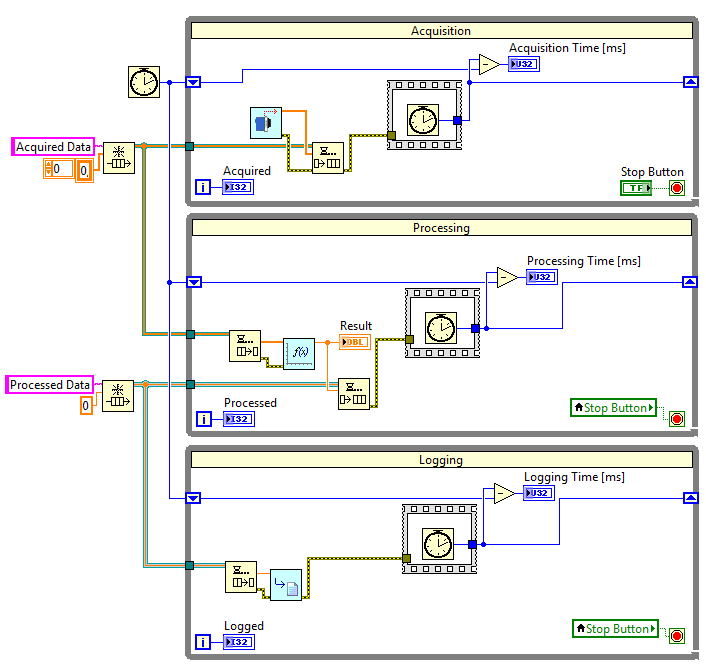
Rysunek 9 Pętle równoległe z licznikami iteracji
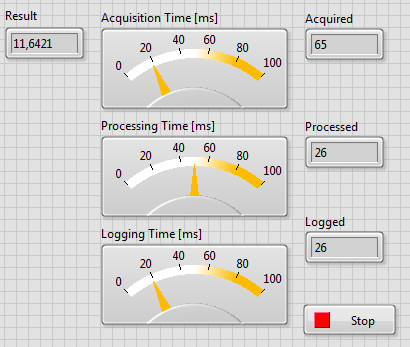
Rysunek 10 Rezultat działania programu po jego zatrzymaniu
Jeżeli zależy nam na tym, aby wszystkie pozyskane dane zostały przetworzone przed zakończeniem programu, nie możemy zatrzymywać wszystkich pętli w tym samym momencie czasowym.
Aby rozwiązać ten problem, oprócz danych do przetworzenia, do kolejki dodawać będziemy komunikaty, informujące pętle równoległe o czynnościach do wykonania. W sytuacji, gdy tą operacją jest przetworzenie lub zapis danych, do kolejki trafią dane wraz z komunikatem odpowiednio Process lub Log, natomiast w przypadku zakończenia, w kolejce umieszczone zostaną puste dane oraz komunikat Stop. Takie rozwiązanie zapewni nam działanie pętli równoległych do momentu przetworzenia wszystkich danych znajdujących się w kolejkach.
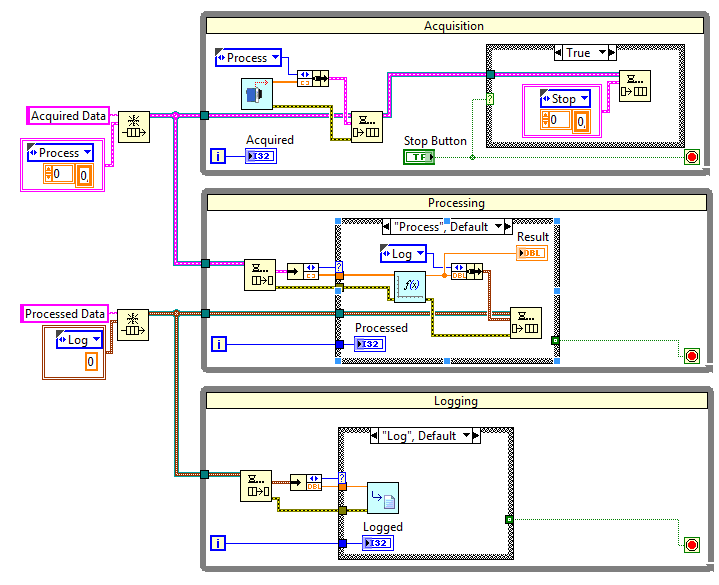
Rysunek 11 Kolejki z komunikatami
W celu oprogramowania tego rozwiązania, zmieniamy typ danych kolejki na klaster złożony ze stałej Enum oraz odpowiednio tablicy i liczby typu double. Do przechowywania wszystkich możliwych komunikatów wykorzystujemy kontrolkę Enum, którą zapisujemy jako definicję typu, a po wykorzystaniu (utworzeniu poszczególnych stałych) usuwamy z diagramu blokowego.
W pętli Acqisition po pozyskaniu danych, pakujemy je w klaster (kontrolka Bundle) razem z komunikatem Process, a następnie tak przygotowany klaster wstawiamy do kolejki. W przypadku naciśnięcia przez użytkownika przycisku Stop Button, do kolejki wstawiamy klaster składający się z komunikatu Stop oraz pustej tablicy oraz zatrzymujemy działanie pętli.
W pętli Processing, pobieramy element z kolejki, a następnie rozpakowujemy klaster (kontrolka Unbundle). W zależności od wartości komunikatu, dokonujemy przetworzenia danych i wstawienia ich do kolejki z komunikatem Log lub zatrzymania pętli i wstawienia do kolejki pojedynczej liczby z komunikatem Stop dla pętli Logging.
W pętli Logging pobieramy w analogiczny sposób dane z kolejki, a w zależności od otrzymanego komunikatu zapisujemy je do pliku lub przerywamy działanie pętli.
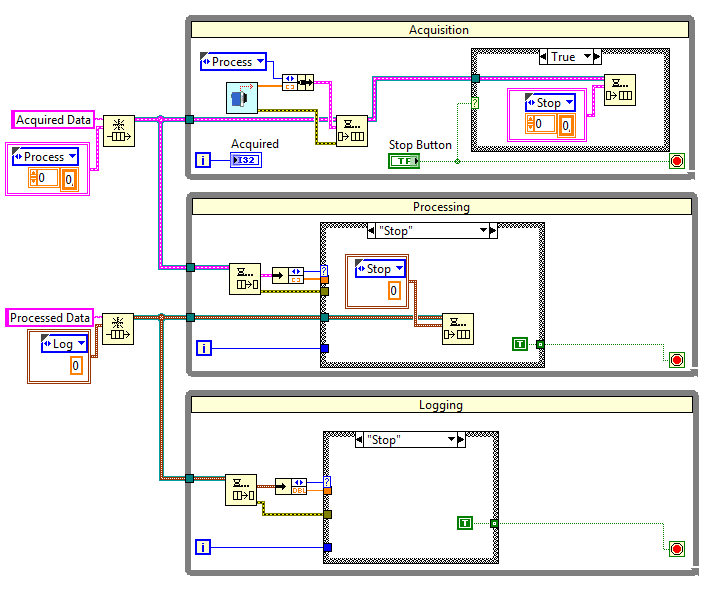
Rysunek 12 Reakcja na komunikat Stop
Po uruchomieniu programu i naciśnięciu przycisku Stop możemy zauważyć, że licznik pierwszej pętli zostaje zatrzymany, natomiast pozostałe pętle działają dalej do momentu przetworzenia wszystkich danych z kolejki.
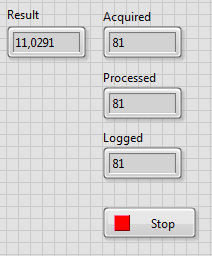
Rysunek 13 Efekt działania programu z komunikatami
Opracowany w ten sposób program możemy dalej ulepszyć, stosując zamiast typu danych specyficznego dla każdej kolejki, typ Variant. Dzięki temu unikniemy konieczności definiowania typu dla każdej kolejki, zastępując go jednym uniwersalnym typem, będącym klastrem złożonym z komunikatu oraz elementu Variant.
W tym celu zmieniamy dane w klastrze na pustą stałą typu Variant, a w poszczególnych pętlach w momencie dodawania danych do kolejki korzystamy z bloczka To Variant. Natomiast pobierając dane z kolejki, przekształcamy typ Variant na pożądany typ danych przy pomocy bloczka Variant To Data.
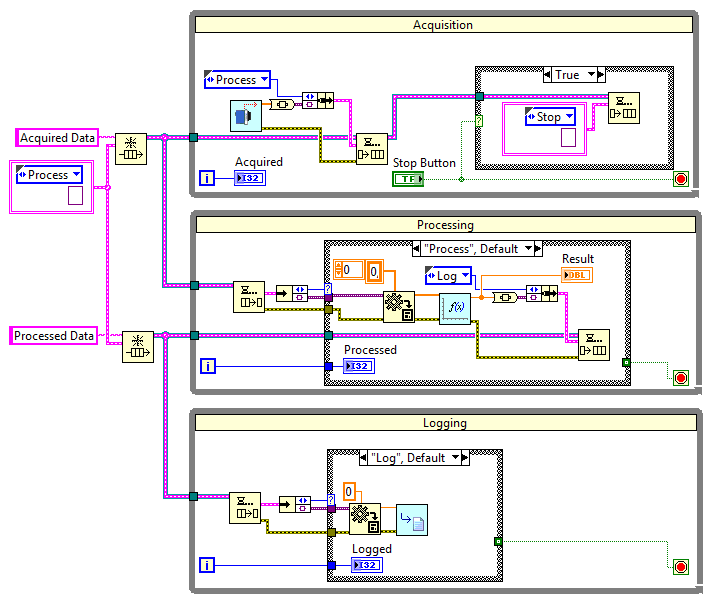
Rysunek 14 Wykorzystanie typu Variant
Propozycje ćwiczeń i modyfikacji
• Zmodyfikować pętlę Acquisition tak, aby generowanie danych nie odbywało się w sposób ciągły, a zdarzeniowo z wykorzystaniem struktury Event
• Dodać do programu paski postępu, informujące użytkownika o aktualnym stanie przetwarzania i logowania danych
• Zapoznać się z dostępnym w LabVIEW szablonem aplikacji Queued Message Handler
Klawiatura ekranowa może przydać się w sytuacji, gdy program potrzebuje nawiązać interakcję z użytkownikiem, a do dyspozycji mamy jedynie ekran dotykowy.
Oprogramowanie klawiatury ekranowej zaczniemy od panelu frontowego.
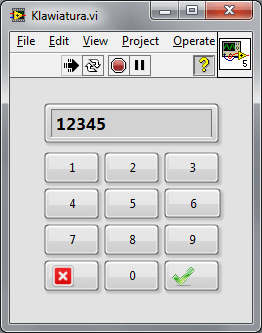
Rysunek 1 Panel frontowy klawiatury ekranowej
Na panelu frontowym umieszczamy 10 przycisków, odpowiadających cyfrom 0-9, przycisk OK oraz Cancel. Każdemu z przycisków nadajemy etykietę (Label) odpowiadającą jego funkcji, następnie tę etykietę chowamy. Dla przycisków odpowiadających cyfrom ustawiamy odpowiedni Boolean Text (tekst wyświetlany na przycisku), przyciski OK i Cancel pozostawiamy bez tekstu. Jako mechaniczną akcję dla każdego z przycisków wybieramy Switch Until Released.
Nad przyciskami umieszczamy wyświetlacz tekstowy String Indicator.
Do oprogramowania zachowania klawiatury skorzystamy ze struktury zdarzeniowej, czyli pętli while ze strukturą Event.
Przechowywany w kontrolce String aktualny napis (początkowo zainicjalizowany pustym stringiem), przesyłamy pomiędzy każdą z iteracji pętli za pomocą mechanizmu rejestru przesuwnego.
Kliknięcie przycisku OK powoduje zakończenie działania programu, bez wpływu na zawartość kontrolki String.
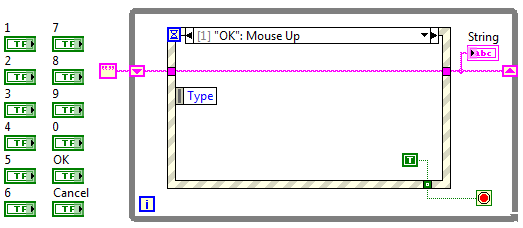
Rysunek 2 Zdarzenie dla przycisku OK
Kliknięcie przycisku Cancel również powoduje zakończenie działania programu, ale do kontrolki String przesyłany jest w tej sytuacji pusty napis.
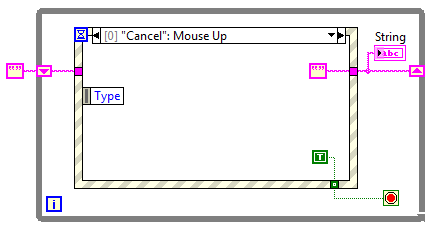
Rysunek 3 Zdarzenie dla przycisku Cancel
Podczas klikania któregokolwiek z przycisków z numerami, do aktualnej zawartości kontrolki String powinien zostać dopisany znak odpowiedni dla danego przycisku.
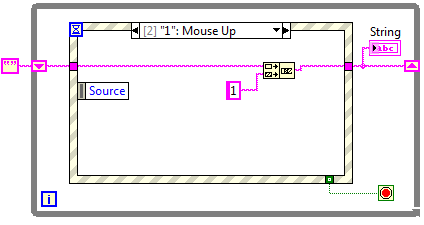
Rysunek 4 Obsługa przycisku "1"
Rozwiązanie takie jak powyższe, jest jednak nieefektywne, ponieważ wymaga od nas utworzenia osobnego przypadku zdarzeniowego dla każdego z przycisków, co w efekcie da 10 przypadków o bardzo podobnej zawartości diagramu blokowego, a w przypadku obsługi pełnej klawiatury alfanumerycznej diagramów tych będzie o wiele więcej.
W środowisku LabVIEW, oprócz informacji o tym, że zaszło określone zdarzenie, mamy do dyspozycji również wiele dodatkowych, szczegółowych parametrów tego zdarzenia. Parametry te dostępne są w strukturze Event Data Node, znajdującej się przy lewej krawędzi struktury Event.
Jednym z dostępnych parametrów jest referencja do kontrolki, która wywołała dane zdarzenie (CtrRef). Wykorzystując tę referencję, możemy za pomocą bloczka Property Node, dostać się do dowolnej właściwości kontrolki, a więc również do tekstu, jaki się na niej znajduje (właściwość Boolean Text -> Text).
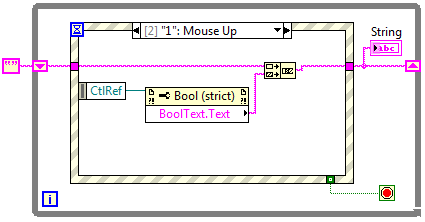
Rysunek 5 Obsługa przycisku "1" z wykorzystaniem referencji
Dzięki takiemu rozwiązaniu, nie ma potrzeby tworzenia dodatkowych diagramów dla każdego z przycisków osobno, wystarczy natomiast skonfigurować zdarzenie dla przycisku „1” tak, aby było wywoływane również w momencie naciśnięcia któregokolwiek z pozostałych przycisków numerycznych. W tym celu klikamy prawym przyciskiem myszy na nagłówku struktury Event i wybieramy opcję Edit Events Handled by This Case…
Następnie do listy zdarzeń dodajemy zdarzenie Mouse Up dla każdego z pozostałych przycisków 0-9.
Jeżeli opracowaną w ten sposób klawiaturę numeryczną chcemy wykorzystać w innym programie, ostatnią z niezbędnych do tego czynności jest podpięcie kontrolki String do jednego z wyjść bloczka, aby umożliwić przesłanie wpisanego przez użytkownika napisu na zewnątrz.
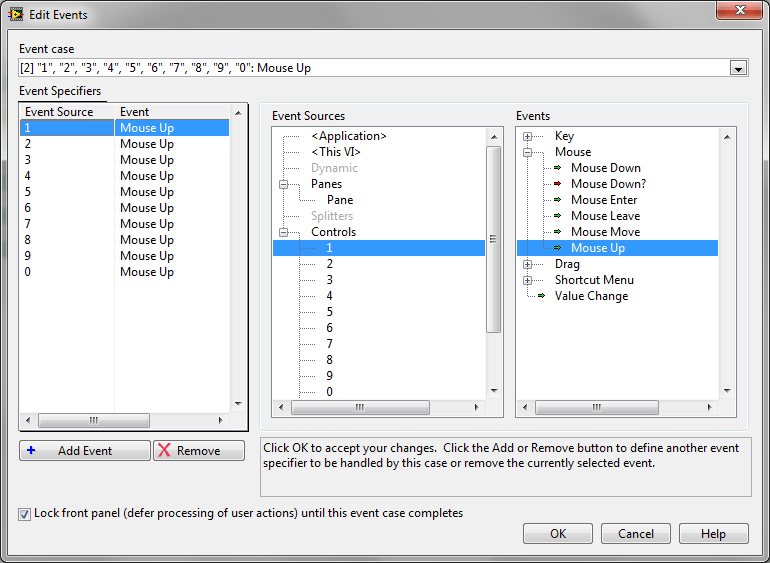
Rysunek 6 Konfiguracja zdarzeń obsługi przycisków "0" - "9"
Propozycje ćwiczeń i modyfikacji
1. W parametrach programu (Menu File -> VI Properties) ustawić opcję wyglądu okienka (Window Apperance) na okno modalne. Skonfigurować pozostałe opcje wyglądu okna tak, aby nie zawierało pasków przewijania oraz górnego menu. Tak przygotowany VI wykorzystać w innym programie do wprowadzenia przez użytkownika danych liczbowych. Klawiatura ekranowa powinna zostać wywołana po kliknięciu w wejściową kontrolkę numeryczną.
2. Dodać do klawiatury możliwość wprowadzania liczb rzeczywistych z zabezpieczeniem przed wielokrotnym wpisaniem znaku separatora dziesiętnego.
3. Dodać do klawiatury przycisk „BACKSPACE”, kasujący ostatni wpisany znak.
4. Dodać do klawiatury przycisk ±, umożliwiający określenie znaku wpisywanej liczby na każdym etapie jej wprowadzania.
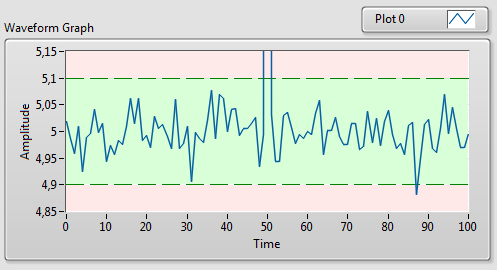
Załóżmy, że oprócz wizualizacji wykresu danych pomiarowych, chcemy również uwzględnić pole tolerancji. Granice pola tolerancji chcemy oznaczyć liniami przerywanymi, a obszar poza polem tolerancji zamalować innym kolorem.
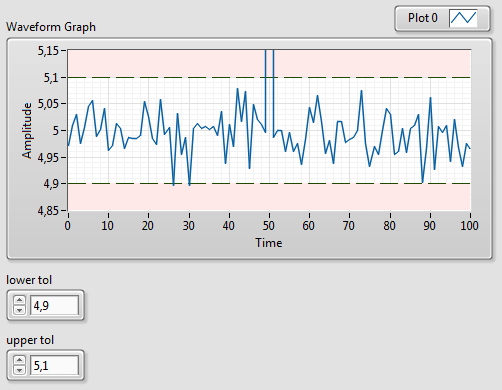
Rysunek 1 Wykres z oznaczonymi polami tolerancji
Zacznijmy od wygenerowania przykładowych danych. Do tego celu wykorzystamy bloczek Gaussian White Noise dostępny w palecie Signal Generation Palette. Jako liczbę próbek ustawiamy 100, odchyleniu standardowemu nadajemy wartość 0,04. Następnie do każdej z wygenerowanych próbek dodajemy wartość 5 (domyślna wartość średnia dla bloczka Gaussian White Noise wynosi 0). W połowie wygenerowanego zbioru próbek wstawiamy wartość 5 podniesioną do kwadratu, aby zasymulować pojawienie się w zbiorze danych pomiarowych zakłócenia w postaci szpilki.
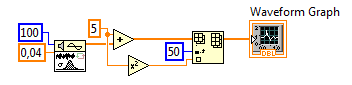
Rysunek 2 Generowanie tablicy danych
Podpinając tak utworzony zbiór danych do kontrolki Waveform Graph, zauważamy, że domyślnie zostanie on wyświetlony z użyciem automatycznego dopasowania skali Y, co w obecności zakłócenia utrudnia analizę. Dlatego oprócz uwzględnienia pól tolerancji będziemy chcieli również dopasować skalę dla osi Y.
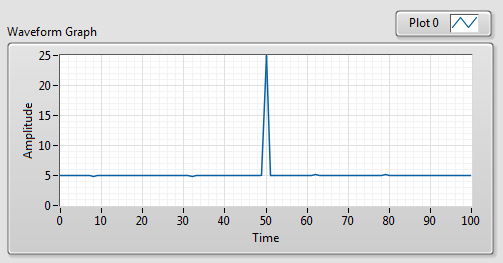
Rysunek 3 Domyślny sposób wizualizacji danych na wykresie w LabVIEW
W celu dodania do wykresu pól tolerancji, tworzymy dwie kontrolki numeryczne – upper tol i lower tol, które będą przechowywać wartość górnej i dolnej granicy tolerancji.
Aby granice tolerancji zostały uwzględnione na wykresie, generujemy dwie dodatkowe tablice danych, o rozmiarach takich jak tablica wejściowa, wypełnione wartościami górnej i dolnej granicy tolerancji. Do tego celu wykorzystujemy pętlę for oraz mechanizm automatycznego indeksowania.
Wygenerowane w ten sposób tablice łączymy w jedną wielowymiarową tablicę przy pomocy bloczka Build Array. Tablicę taką możemy już podpiąć do kontrolki wyświetlającej wykres Waveform Graph.
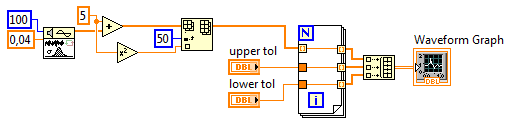
Rysunek 4 Wygenerowanie tablic dla pola tolerancji
Wyświetlony w ten sposób wykres zawiera trzy zbiory danych, jednak jego skala ciągle jest dopasowana do minimalnej oraz maksymalnej wartości w zbiorze.
W celu zmiany skali na osi Y, wykorzystamy możliwość programowego ustawienia parametrów kontrolki Waveform Graph przy pomocy bloczka Property Node.
W tym celu klikamy prawym przyciskiem myszy na bloczku Waveform Graph, a następnie z menu wybieramy opcję Create -> Property Node -> Y Scale -> Range -> Maximum. Utworzoną w ten sposób kontrolkę rozciągamy w dół, aby uzyskać dostęp do właściwości Minimum dla skali osi Y.
Załóżmy, że chcemy aby skala osi Y wykresu była tak dopasowana, by obszar odpowiadający polu tolerancji zajmował 2/3 centralnej części wykresu. W tym celu do górnej granicy pola tolerancji dodajemy wartość będącą ¼ szerokości pola, a od dolnej granicy tę wartość odejmujemy. Tak obliczone wartości podpinamy do wejść utworzonego wcześniej bloczka Property Node dla kontrolki Waveform Graph.
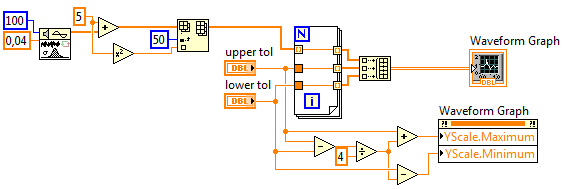
Rysunek 5 Dopasowanie skali osi Y w zależności od szerokości pola tolerancji
Dzięki temu, obecna w danych pomiarowych szpilka została usunięta poza obszar wykresu, mimo to dzięki obecności linii łączących poszczególne punkty wykresu, nie tracimy całkowicie informacji o jej wystąpieniu.

Rysunek 6 Wykres z automatycznie dopasowaną skalą osi Y
W celu osiągnięcia ostatecznego pożądanego wyglądu wykresu, konfigurujemy odpowiednio sposób wyświetlania danych dla zbiorów odpowiadających granicom pola tolerancji.
W omawianym przykładzie dane te zostały wyświetlone z użyciem linii kreskowanej koloru zielonego o odcieniu (R:0, G:128, B:0). Aby uzyskać efekt zamalowania obszaru poza polem tolerancji, ustawiamy opcję wypełnienia do +nieskończoności dla granicy górnej, a –nieskończoności dla granicy dolnej. Jako kolor wypełnienia wybieramy blady odcień czerwonego (R: 255, G:232, B:232).

Rysunek 7 Konfiguracja sposobu wyświetlania danych dla granicy tolerancji
Propozycje ćwiczeń i modyfikacji
1. Opracować wizualizację danych w taki sposób, aby obszar wewnątrz pola zamalowany został kolorem zielonym, a obszar poza polem kolorem czerwonym:
Rysunek 8 Oczekiwany rezultat ćwiczenia
2. Zwizualizować na jednym wykresie dwie serie danych pomiarowych o różnych (lecz zbliżonych do siebie) wartościach średnich i polach tolerancji. Dopasować sposób dostosowania skali osi Y, aby wykres był czytelny.
Baza wiedzy mvlab → Posty przez Dariusz Tryba